The Challenge
The primary objective of the AI Research Retrieval (AIRR) project was to determine if Large Language Models (LLMs) could reliably produce factual and trustworthy responses utilizing specific National Library of Medicine (NLM) sources. Addressing this required confronting the known limitations of AI, including the potential for vulnerable code, the trade-off between efficiency and accuracy, and the documented user tendency to not verify answers from medical QA systems (at least 95% of developers surveyed spend extra time fixing AI-generated code, and only about one-third of study participants clicked links to verify medical QA answers). The core difficulty lay in balancing the speed and scalability of AI generation with the absolute necessity of ensuring scientific rigor, safety, and alignment with strict NLM policies against providing medical advice or diagnoses.
Our Solution
Our solution centered on the foundational principle: Technology + Humans = AI Trustworthiness. We deployed a sophisticated Retrieval Augmented Generation (RAG) pipeline built on serverless architecture to integrate evidence-based NLM sources into the LLM output. A unified engineering pipeline was developed by combining the template-based approach—used to structure responses according to question categories—with the Chain-of-Thought (CoT) reasoning pipeline, enabling both contextual structure and deeper logical inference.
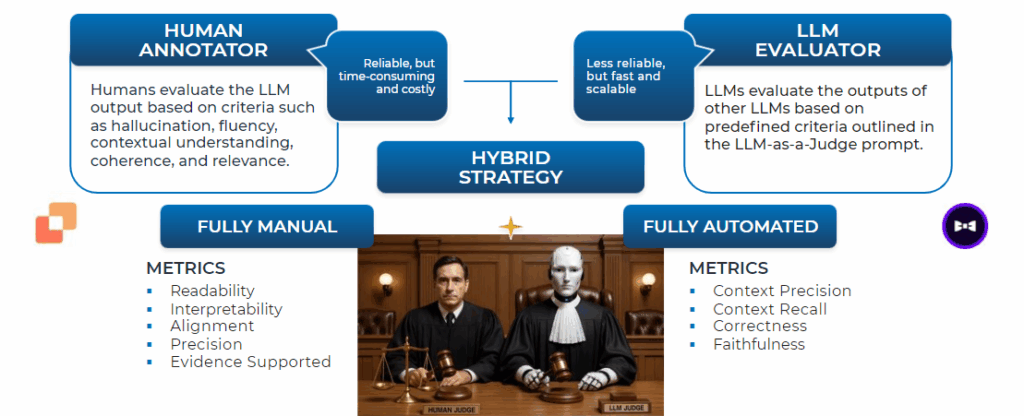
In parallel, we implemented a robust “Humans in the Loop” (HITL) practice, uniting human and machine intelligence to create a continuous feedback loop. This involved recruiting 32 NIH Subject Matter Experts (SMEs) as human annotators across two evaluation phases to provide biomedical subject matter expertise. We utilized a Hybrid Evaluation Strategy, combining the precision and reliability of these human annotators—who evaluated criteria like readability, interpretability, accuracy and relevance—with the efficiency of LLM Evaluators (aka LLM-as-a-Judge). Additionally, we applied structured prompt engineering and response templates to systematically improve the output quality, accuracy, and consistency of the system.
Results
The structured development and HITL approach measurably improved quality across key metrics. Between Phase 1 and Phase 2, human annotation scores for Alignment (ensuring responses contained no medical advice, diagnosis, PII/PHI, or unsuitable content) increased by +39.7%. Other essential metrics, such as Readability, improved by +14.7%.
The project successfully indexed 50K knowledge documents, created 130 Q&A benchmark datasets, and established two fully evaluated pipelines. Beyond these technical achievements, the project transformed the understanding of AI development among participating staff; annotator feedback emphasized the absolute necessity of accuracy, consistency, and attention to detail in labeling data for AI models.
The effort provided key lessons learned, including documenting best practices and a foundational strategy for long-term safety, reliability, and continuous improvement necessary to track model drift and integrate ongoing feedback loops.
